The Latest from TechCrunch |  |

- The Future of Science
- Data Driven Decisions for Startups
- Google Releases Full Report On Street View Investigation, Finds That Staff Knew About Wi-Fi Sniffing
- No, AirPlay Is Not The New Apple TV
- Hardware Start-Ups: Join Us In Hardware Alley At TechCrunch Disrupt NY
- HTC One S Review: I Give It A Fly
- Lane Becker On How To ‘Plan Serendipity’ In Tech And Business [TCTV]
- The Seven Forces Disrupting Venture Capital
- Cyberpunks Rejoice: Kickstarter Project Aims To Resurrect Shadowrun
- Gillmor Gang: The Teddy Bear Bubble
- They Ain’t Making Any More of Them: The Great Engineering Shortage of 2012
| Posted: 29 Apr 2012 08:00 AM PDT  Editor’s note: This guest post was written by Richard Price, founder and CEO of Academia.edu — a site that serves as a platform for academics to share their research papers and to interact with each other. Almost every technological and medical innovation in the world has its roots in a scientific paper. Science drives much of the world's innovation. The faster science moves, the faster the world moves. Progress in science right now is being held back by two key inefficiencies:
The stakes are high. If these inefficiencies can be removed, science would accelerate tremendously. A faster science would lead to faster innovation in medicine and technology. Cancer could be cured 2-3 years sooner than it otherwise would be, which would save millions of lives. The time-lag problem The first major inefficiency is the time-lag problem for distributing scientific ideas. After you have written a scientific paper, it takes, on average, 12 months for the paper to be distributed to the global scientific community. During that time the paper is going through the peer review process, which takes an extremely long time. If you read a paper, and have some thoughts about it, and write up a response, it is going to take 12 months for your response to be seen by the global scientific community. Science is fundamentally a conversation between scientists around the world. Currently the intervals between iterations of that conversation are 12 months on average. This 12 month time-lag represents a huge amount of friction in the circulation of scientific ideas. Imagine the slowdown on the web if every blog post, and every tweet, and every photo, was made available on the web 12 months after it was originally posted. Imagine if all the stories in your Facebook News Feed were 12 months old. People would be storming the steps of Congress, demanding change. The time-lag in the distribution of scientific ideas is significantly holding back science. It's critical for global progress that we work to remove this inefficiency. The single mode of publication problem Historically, if a scientist wants to make a contribution to the scientific body of knowledge, it has to be in the form of a scientific paper. Blogging hasn't taken off in science, because scientists don't get credit for writing blog posts. You often hear a scientist saying 'I'm not going to put these ideas in a blog post, because they are good enough for me to incorporate into a paper, which I'll publish in the next couple of years'. Everyone loses out because of that delay of a couple of years. Most people who share information on the web have taken advantage of the rich media that the web provides. People share information in all kinds of forms: videos, status updates, blog posts, blog comments, data sets, interactive graphs, and other forms. By contrast, if a scientist wants to share some information on a protein that they are working on, they have to write a paper with a set of two dimensional black and white images of that protein. The norms don't encourage the sharing of an interactive, full-color, 3 dimensional model of the protein, even if that would be a more suitable media format for the kind of knowledge that is being shared. The future of science: instant distribution Tim Berners-Lee invented the web in order to make it easier for him and his colleagues to share their research papers. The web has impacted science, but over the next few years, the web is going to entirely re-invent the way that scientists interact. In 5-10 years' time, the way scientists will communicate will be unrecognizable from the way that they have been communicating for the last 400 years, when the first academic journal was founded. The first change will be instant distribution for all scientific ideas. Some sites, such as arXiv, Academia.edu, Mendeley, and ResearchGate have brought instant distribution to certain sub-fields of science recently, and this trend is going to continue to all fields of science. In a few years, scientists will look back and will struggle to believe that they used to exist in a world where it took 12 months to circulate a scientific idea around the world. Discussing the idea of 12 month distribution delays for ideas will produce the same confused look that it produces today, when one asks someone to conceive of 12 month distribution delays to tweets, blog posts, and general web content. Instant distribution means bringing the time-lag for distributing a scientific paper around the world down to 1 day, or less. This speed-up will have a transformative effect on the rate of scientific progress in the world. Discoveries will be made much more quickly. One of the reasons that technological progress in the 20th century was so much greater than growth in previous centuries is that there were so many powerful communication technologies invented in the 20th century that connected people around the globe: the telephone, the TV, the internet. Bringing instant distribution to science will have a similarly transformative effect on scientific progress. The future of science: rich media Historically scientists have written their papers as native desktop content. They have saved their papers as PDFs, and uploaded the files to the web. Over the next few years, scientific content will increasingly become native web content, and be written natively for the web. Scientific content will be created with the full interactivity, and richness, of the web in mind. Most papers are downloaded from the web, and printed out by scientists for reading. The content was written in such a way that it's fully readable in print-out form. Most web content is inherently rich. No-one prints out their Twitter and Facebook News Feeds to read them, or blog posts. The idea of printing out content doesn't make sense for much of the web's content, such as YouTube videos, Facebook photos, interactive maps, and interactive graphs such as those on you find on Quantcast, or Yahoo Finance. The hyperlink itself is a piece of interactivity built into web content. One reason you don't want to print out a Wikipedia article to read it is that the page is full of useful links, and you want to be adjacent to that interactivity when reading the article to take advantage of the full power of the article. Historically, scientific papers have cited other papers, but those citations are not hyper-linked. To citizens of the web, the idea of referring to some other page without linking to it seems an impossibly old-fashioned way of sharing content. Imagine reading a blog, or a Facebook News Feed, where there were no links, and everything was plain text. Instead, there was a set of references at the end of the page, and those references told you were to find certain other pages on the web, but the references weren't themselves hyperlinked. A citation to a video would something like "YouTube.com, Comedy section, page 10, "Coke bottle exploding", video id = 34883". You would then have to go to YouTube and navigate to the right section to get the video that has that title. This experience would indeed be a nightmare. The difference between that, and how the web currently is, is the difference between where scientific communication is right now, and where it will be in a few years, when scientists fully adopt the rich media of the web. Scientists will share content in whatever format makes sense for the piece of content in question. They will share ideas in the form of data sets, videos, 3-d models, software programs, graphs, blog posts, status updates, and comments on all these rich media. The ways that these content formats will connect with each other will be via the hyperlink, and not via the citation. The citation will look like an ancient concept in a few years. Science is undergoing one of the most exciting changes in its history. It is in a transition period between a pre-web form of communication to a natively web form of communication. The full adoption of the web by scientists will transform science. Scientists will start to interact and communicate in wonderful new ways that will have an enormous effect on scientific progress. The future of science: peer review In a world of instant distribution, what happens to peer review? Will this be a world where junk gets published, and no-one will be able to tell whether a particular piece of content is good or bad? I wrote a post on TechCrunch a few weeks ago called "The Future of Peer Review", arguing that the web has an instant distribution model, and has thrived. I argued that the web's main discovery engines for content on the web, namely search engines, and social networks, are at their heart, evolved peer review systems. These web-scale peer review systems, search engines and social networks, already drive most discovery of scientific content. The future of science: academic credit Historically scientists have gained credit by publishing in prestigious journals. Hiring committees, and grant committees, historically have looked at the kinds of journals a scientist has managed to get published in as a measure of the quality of the scientist's work. In the last few years, such committees have also started to look at citation counts too. As scientific content moves to become native web content, scientific content will increasingly be evaluated according to the kinds of metrics that reflect the success of a piece of content on the web. Web metrics vary, and evolve. Some are internet-wide metrics, such as unique visitors, page views, time on site. Others are specific to certain verticals, or sites, such as Twitter follower counts, StackOverflow score, Facebook likes, and YouTube video views. As these metrics are increasingly understood in the context of scientific content, scientists will increasingly share content that attracts this kind of credit. If you can share a data-set, and collect credit for it, you will. If you can comment on a paper, and collect credit for it, you will do that too. If sharing a video of a process is more compelling than having black and white images of the process, videos will take off. Directing Silicon Valley's resources towards accelerating science Science is in the process of being re-built and transformed. It is going to be an exhilarating process. The positive impact to society will be significant. The next wave of science is not being built by scientific publishers. It is being built by engineering-focused, Silicon Valley tech companies. It is being built by talented and visionary engineering and product teams. Silicon Valley's formidable resources are starting to turn in the direction of science, having been focused for the past 2-3 years on areas like optimizing strawberry credit flows on FarmVille. Venture capital, entrepreneurial talent, and engineering talent is starting to flow into the space, and the future of science is starting to be built. The ecosystem needs more resources. It needs more engineers, entrepreneurs, and venture capital. The prizes for success in transforming science go to everyone in the world. $1 trillion a year gets spent on R&D, of which $200 billion is spent in the academic sector, and $800 billion in the private sector. There are vast new companies waiting to be built here. As the extraordinary Silicon Valley innovation engine increasingly directs itself at transforming science, you can expect to see acceleration on a scale that science has never seen. Science will change beyond recognition, and the positive impact on the rate of technology growth in the world will be enormous. The time to act is now. If you are a VC, invest in science startups. If you are an entrepreneur, hunt for an idea in the space and run with it. If you are an engineer or designer, there is a list of startups trying to accelerate science here.
      |
| Data Driven Decisions for Startups Posted: 28 Apr 2012 10:30 PM PDT  Editor’s note: Uzi Shmilovici is the CEO and founder of Future Simple, the company behind Base CRM. "If you don't have any facts, we'll just use my opinion." – Jim Barksdale (former president and CEO of Netscape). Startups are the sum of the decisions made by the people who run them. Should you raise money? Who should you raise money from? What should be your marketing strategy? What are the next features you should build? Who should you hire? Ok.. you get the point. If decisions are so important then it might be worthwhile to think about how to make them better. A lot of research has been done on this subject and you can literally spend years going through the books, papers and the various theories and schools of thought in decision-making. Needless to say, that will probably be a bad decision by itself. Instead, it is more important to understand why data driven decisions work and to instill such a culture in your company. Why Data Driven Decisions Work From all the papers written on the subject, there was one paper that left a huge impression on me. In 1979 the late psychologist Robyn Dawes wrote a paper titled "The robust beauty of improper linear models in decision making". The idea is simple. Prior research discovered that a decision made using a good professional objective decision-making model will always trump expert intuition. The breakthrough in Dawes' work was the finding that even improper, simple, "stupid" models are better than intuition. Let's put that into context and talk about hiring. Say you want to hire for a new position. Building a proper model would require you to collect and analyze all data about people you hired so far and come up with a statistical model to evaluate and identify the top candidates based on various parameters. This is what Google does. However, Google has a LOT of data since it hired tens of thousands of people so far. As a startup, you don't. Turns out that you can build a simple model based on what you think are the important parameters of a candidate and then evaluate candidates based on that model. More importantly, it will force you to think analytically about what are the important parameters to consider for that specific role. This by itself will lead to a better decision and will remove subjective biases. This is why data driven decisions are so powerful. Instrument Everything The idea from Dawes' paper can be extended to other areas in your startup. Almost everything that you do can be boiled down into a formula. Doing that will force you and your team to think about what are the critical parameters for success in any given project or initiative and then better optimize for that success. As mentioned before, as a startup you don't have a lot of data. There are many resources online that you can use on day one. For instance, if you are building a marketing model and are wondering what is an average conversion rate for the freemium model, you can find an answer. However, it is critical that you start collecting data from day one so you can make more accurate estimations and as a result, better decisions. Jack Dorsey and The Inference Team I am not a fan of the "before and after" marketing tactic but it works well because it focuses on results. In the case of the data driven startup, one of the most interesting cases is the case of Jack Dorsey who has seen the power of data driven decisions and made it his job to put together an "inference team" at Square. This team focuses on collecting and analyzing data to make better decisions. In his words: "For the first two years of Twitter's life, we were flying blind… we're basing everything on intuition instead of having a good balance between intuition and data… so the first thing I wrote for Square is an admin dashboard. We have a very strong discipline to log everything and measure everything." Amen. Start Now The earlier you start collecting, analyzing and inferring from data, the better your decisions will become. A year from now you may wish you had started today. If you are interested in decision-making theory, then you should really spend time reading about Prospect Theory – the Nobel Prize winning work of Daniel Kahneman and Amos Tversky. It will give you a good grip about how we make decisions and what are the common biases we fall into.
  |
| Google Releases Full Report On Street View Investigation, Finds That Staff Knew About Wi-Fi Sniffing Posted: 28 Apr 2012 09:11 PM PDT  Earlier today Google released the full report of the FCC’s investigation into the collection of “payload data” from open Wi-Fi networks — aka passwords, email and search history from open networks — that its fleet of Street View cars obtained between 2008 and April 2010. An earlier and heavily redacted version of the report was released on April 15 but today’s version only redacted the names of individuals. The report found no violation of any wrong doing by the company because there was no legal precedent on the matter. The FCC found that Google did not violate the Communications Act citing the fact that Wi-Fi did not exist when it was written. However, the FCC did fine Google $25,000 for obstructing the investigation, which was presumably the outcome of Google refusing to show the FCC what the data being collected entailed because it might have shown that the company broke privacy and wiretapping laws. Google says any obstruction was result of the FCC dragging out the investigation. Interestingly enough, the report did reveal that the data harvesting was not the act of a rogue engineer and that said engineer notified the Street View team of what was going on. (Wait. What? Google knew this was going on! It gets even better.) Except that those members of the team told the FCC that they had no idea it was going on even though the engineer in question sent documentation of the work being done to the entire Street View team in October of 2006. The report also found that up to seven engineers had “wide access” to the plan to collect payload data dating back to 2006. From the report:
For a little more background, let’s examine what Alan Eustace, Senior VP, Engineering & Research blogged back in 2010:
Fair enough. But the following excerpt from the report doesn’t quite sit so well with me: "We are logging user traffic along with sufficient data to precisely triangulate their position at a given time, along with information about what they were doing." To be more specific, the last portion about knowing “what they were doing” seems a bit peculiar. Why would Google need to know what they were doing? Seems irrelevant if you’re just mapping the location of networks, doesn’t it? So how did Google spin this to the media? It said the data mining was “inadvertent” and that Google now has stricter privacy controls than in the past. Oh and the company hopes the release of the full report would allow them to “put this matter” in the rear view mirror. Crazy, right? Or maybe not! Discuss. Correction: April 28, 2012 9:46PM PT An excerpt from the report has been added regarding the pre-approval of a document sent out by “Engineer Doe” to the Street View team that detailed the work being done and included the fact that Google would be collecting such data.
  |
| No, AirPlay Is Not The New Apple TV Posted: 28 Apr 2012 08:14 PM PDT  Editor’s note: David McIntosh is the founder and CEO of Redux, a fast-growing video discovery company. Redux is the top downloaded app on Google TV, and you can read David's other guest posts here. If you asked your mom or dad what DLNA or UPnP stood for or did, would they just look at you weird? While the two technologies enable users to wirelessly beam content to Internet Connected TVs from their tablets, phones, and computers, Apple's AirPlay is the first implementation that makes the experience seamless. Tap the button again and playback resumes on your root device. No complicated setup is required – it simply works. Some, like Bloomberg and Hunter Walk, have suggested that AirPlay is Apple TV, and that Apple will simply license AirPlay to the major Connected TV manufactures – and by default every Connected TV sold will be an “Apple TV” – the remote being your iPhone or iPad. It’s certainly a sensible theory – there are 250 M+ iOS devices, and with the upcoming OS X update, laptops can now leverage Airplay as well. That’s over 300M Apple devices that can push content to TVs. Fragmentation is the reality That level of integration would be a dream come true for many networks, studios, and cable companies looking to sell a "TV Everywhere" experience directly to users. Simply integrate with an iOS app, and with one tap consumers can watch content on hundreds of TV devices. Today it's a big competitive advantage to be able to offer a consistent and incredible TV experience across hundreds of devices. Netflix built its early lead around that competitive advantage, and many networks, studios, and cable companies are looking to build technological solutions to combat fragmentation so that they can compete with Netflix. A content network or studio needs to be able to deliver a discovery and consumption experience better than Netflix's across just as many devices — otherwise the consumer will turn to Netflix. A ubiquitous AirPlay integration would level the playing field considerably, but is unlikely for several reasons: (1) AirPlay adoption is not wide yet. There are less than 5M Apple TV units in the market, which means that today there are less than 5M users in the market that use Airplay for video. And while Apple is heavily promoting AirPlay-video-enabled apps in the iTunes store, wide consumer adoption is unclear. Unfortunately, stats on Airplay usage aren’t widely available, but anecdotally – in my group of friends I'm the one evangelizing it – many Apple TV owners I meet don’t even realize AirPlay exists. (2) Manufacturer adoption will be slow. Given that AirPlay does not have a critical mass of users, it’s hard to imagine how in the short-term Apple will convince any of the top five TV manufacturers to adopt AirPlay. Margins on TVs have been decreasing over time, and manufacturers are looking to integrate Connected TVs into an ecosystem of higher-margin tablets and phones. Integrating AirPlay,while it may sell more TVs (when Airplay has critical mass) will reduce sales of higher-margin tablets and phones they could have sold that exclusively interfaced with their TVs. (3) A seamless experience is unlikely. It’s unlikely video AirPlay would be integrated consistently across all Connected TVs to create the same seamless experience consumers have with an Apple TV today. DLNA is a good example. It'’s an open protocol that in theory should accomplish what AirPlay does, except it’s implemented inconsistently across devices and often doesn't work at all. Unless Apple has full control of the software layer, simply licensing out AirPlay would not achieve the desired experience. Apple can overcome the issue of critical mass with enough of its own Apple TV units in the market. But at the pace of sales for its existing Apple TV, it will be years before AirPlay would have the usage to give Apple the clout to get integrations with other manufacturers. That's why the rumors of an upcoming integrated Apple TV or upgraded device make sense. While AirPlay may be the long-term bet, in the short-term Apple needs a critical mass of users airplaying content to their TV. And AirPlay may be a central part of the rumored AppleTV. It wouldn't be surprising if Apple uses their new device to train users how to use AirPlay. At that point, AirPlay could become a must-have for other TV manufacturers. As a TV manufacturer you would lose sales by not having it integrated. But even with a critical mass of AirPlay users in the market, it's still unclear whether Apple could convince many manufacturers to adopt AirPlay, or would even have success getting them to implement it the way it's implemented in Apple TV. That's why Apple owns the hardware and software layer; they can create experiences that would never be created by leaving third-party manufacturers to their own devices. Winners in TV will have technological solutions to fragmentation What's more, a fragmented approach to DLNA and Connected TV has already developed. Just as the Android ecosystem is increasingly fragmented, while iOS is uniform, the Apple TV of the future will be nicely unified with other iOS devices through AirPlay, whereas other Connected TVs will have fragmented platforms with fragmented DLNA protocols. That means that succeeding in the fast-growing Connected TV ecosystem will require a killer approach to fragmentation. Leading cable companies, and networks looking to sell directly to consumers will have to sit on top of iOS's uniform AirPlay platform, as well as a highly fragmented Connected TV and DLNA platform to reach meaningful scale. There’s also the issue of whether or not Apple can strike a deal with Hollywood and other content creators but that’s a story for some other time.
  |
| Hardware Start-Ups: Join Us In Hardware Alley At TechCrunch Disrupt NY Posted: 28 Apr 2012 05:30 PM PDT  TechCrunch Disrupt is all about start-ups but we often give short shrift to hardware-based companies. Well, that’s about to change because we’re now running Hardware Alley, a one day exhibition of some of the coolest hardware start-ups in NY and beyond. Running a Kickstarter project? Building a better mousetrap? Creating something cool out of scrap metal and wires? Register as a Hardware Alley exhibitor. You’ll get admission on the last day of Disrupt, May 23, a table to show off your goods, and access to some of the most interesting people (and most interesting VCs) in the world. We’d love to have you. Email Matt Burns (matt@techcrunch.com) with the subject of “I Want To Be In Hardware Alley” for more pricing and more information. He also likes cats gifs. There is a limited amount of space so hit him up quickly.
  |
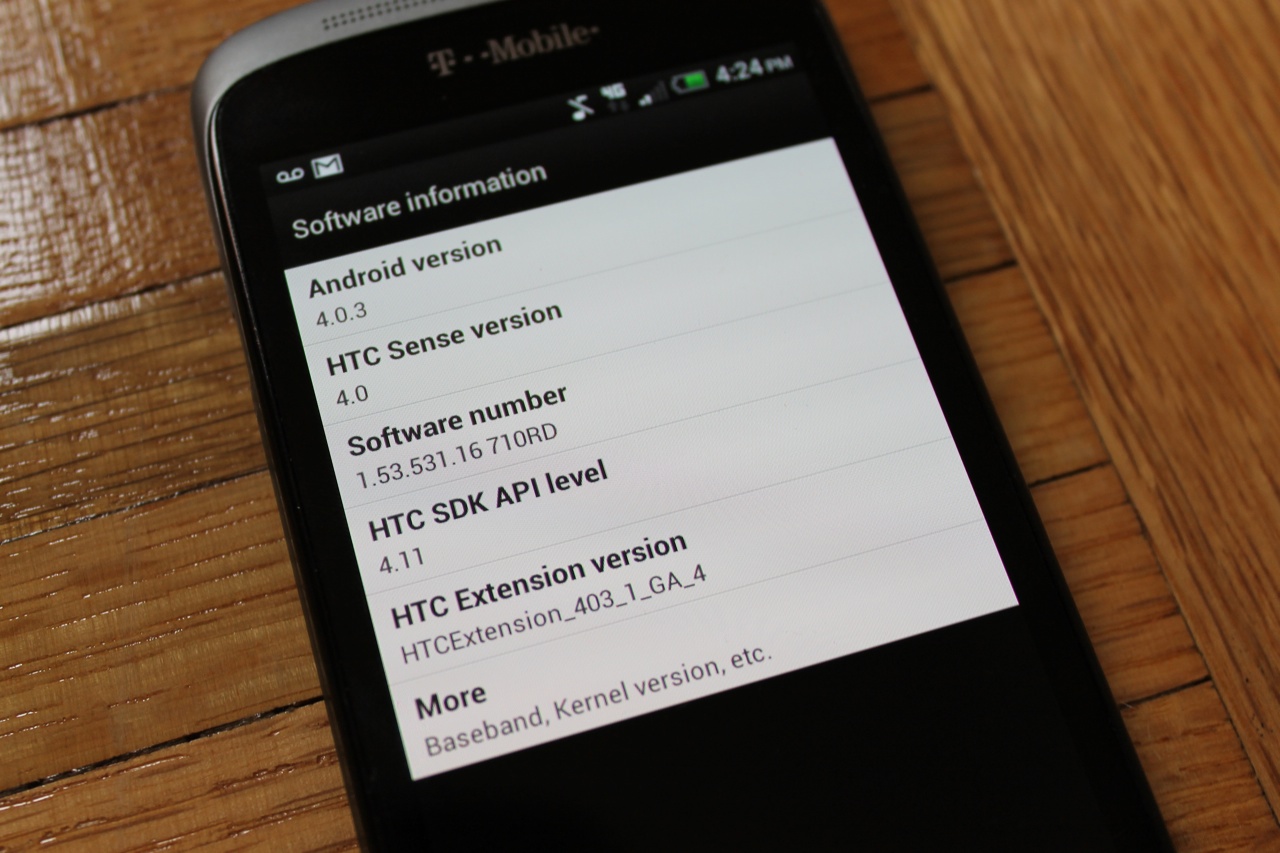
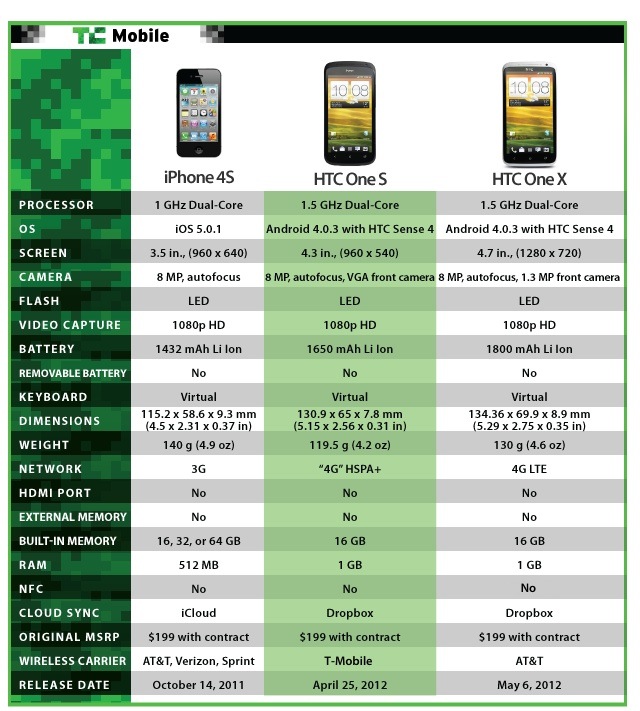
| HTC One S Review: I Give It A Fly Posted: 28 Apr 2012 02:30 PM PDT  Short VersionDespite the fact that there’s no real wow factor here, it would be entirely unfair to say that HTC’s One S isn’t a great phone. It is. The hardware is some of the best I’ve seen in a long time, Sense 4 is quite nice albeit a touch heavy for my taste, and the specs are right in line with what we’re seeing on the market today. Truth be told, anyone at T-Mobile would be lucky to have one. S. (Lawl.) Features:
Pros:
Cons:
Long VersionHardware/Design: As I’ve said twice already, I’m truly impressed with this hardware. It sports an aluminum unibody frame, with a soft-touch finish. The back fades from a lighter to a darker grey, and when all is said and done, it’s a stunning device. Android phones these days are so plastic-y, too light to feel premium, and seem to be thrown together. However, it’s clear with the One S that HTC spent time on design and build quality. The phone is super thin with a .37-inch waistline and weighs in at just 4.22 ounces. I usually don’t spend a lot of time talking about weight and dimensions because most phones are actually quite similar in that respect, but HTC hit the nail right on the head with the One S. Here’s why: if a phone is too thin, and thus too light, it begins to feel cheap — especially when it’s made entirely from plastic. Since the One S is made of aluminum, it’s able to maintain a thin profile while still having a balanced, solid heft to it. This allows the phone to feel way more high-end than most of its competition. The phone is relatively flat on both the front and back, though all the corners and edges are slightly rounded. As I said, it has a beautiful design and solid hardware. The camera sits square on the back of the phone and sports a nice little blue trim to add a little style to a rather grey device. If you like a pop of color, you’ll surely appreciate the detail. Along the left edge you’ll find an MHL-style micro-USB port, which also doubles as HDMI out, and on the right edge you’ll find the volume rocker. A 3.5mm headphone jack and the lock button share space on the top edge of the phone. Software: The HTC One S runs Android 4.0.3 Ice Cream Sandwich, though you’d be hard-pressed to recognize it. Sense is one of the heaviest OEM skins on the market, and it completely dominates the phone. That said, Sense is actually a pretty beautiful UI. Sense 3 and all of its iterations was way too much. 3D animations abounded, frills and flourishes were everywhere, and most of it was entirely arbitrary. Much of that has been cleaned up to actually serve a purpose. See, as John and I mentioned in our Fly or Die episode with the One S, Android has become a platform that pumps out phones from hundreds of vendors that ultimately look like “just another Android phone.” The skins become critical to manufacturers in terms of differentiation, but they also have to be careful to leave Android alone in many respects. Android fans love Android, not Sense or TouchWiz or whatever else. Still, I think HTC did a good job of reigning in all the creativity and letting Sense be useful rather than overly beautiful. The camera app is quite wonderful, which I’ll discuss more in a second, and the widgets provided make it easy to customize the One S to suit you specifically. I’m using a pretty bad ass analog clock right now on my main homescreen that I’m quite proud to show off. Camera: The One S camera is quite capable. In fact, you’ll probably really like the images you capture with it. At the same time, I wouldn’t say the camera is all that good at keepin’ it real, if you know what I mean. Colors seem to be saturated and brightened to make images more beautiful, especially yellows and reds. If you take a look at the comparison shot below, you’ll notice that the iPhone 4S makes my food look a little bland. (It’s delicious, in case you’re wondering.) But when I hold both phones up next to the food, the iPhone 4S clearly captured reality way better than the One S. In terms of software, the Sense camera app may be my favorite of all the Android phone makers’ camera software variations. It has a variety of filters that are built right in to the app, and I’d say some of them (like Vintage) rival those of Instagram. There are also plenty of settings for ISO, White Balance, etc. Comparison shot between the One S (left) and the iPhone 4S (right): Display: I have very few complaints when it comes to the One S display. At 4.3-inches, it’s absolutely the perfect size to be comfortable in the hand while maintaining a nice pixel density. qHD — or 960xb540 — is perfectly acceptable on a 4.3-inch display. And the Super AMOLED quality only adds to that. You really don’t notice any pixel-to-pixel differentiation, and images and videos look great. I did notice that when the phone fires up, there’s a small, rectangular block on the top right of the phone where the screen displays that the software is loading up. It looks like any other progress bar you’ve seen before, but when the progress bar disappears that little block of pixels is much whiter than the rest of the start-up screen. This is a minimal, if not entirely unimportant, issue. It makes no difference whatsoever, as that same block doesn’t show any weird coloration or pixelation when the phone is turned on and working. Performance: Wow! The One S has tested better than the Note, the Droid 4 and the LG Spectrum in both Browsermark and Quadrant. Quadrant tests everything from the CPU to the memory to the graphics, and while all three of the aforementioned Android phones stayed well below the 3,000 mark, the One S scored an impressive 4,371. Same story applies in the browser-based Browsermark test. The Spectrum, Droid 4, and the Note all scored below 60,000, while the One S hit 100,662. I’m totally impressed, but not by the numbers. True, there’s a general lag that comes along with Android, especially in the browser. Pinch-to-zoom and scrolling simply aren’t as smooth as they are on iOS, or even on Windows Phone for that matter, even if it’s minimally. But the One S felt more frictionless than I’m used to on Android, and I never experienced a freeze of any kind. It’s a nice change from most Android reviews. Speed test was a bit of a different story. Of course, in different parts of the city, I had my highs and lows in terms of a speedy network. But during testing Speedtest only saw an average of 2.11Mbps down and .73Mbps up. Battery: I’m pretty impressed with the One S battery. Around the mid-way point of testing I had a bad feeling. The phone displayed about a quarter of juice in the little battery icon, but it lasted another two hours or so. I’m thinking the icon itself is off, to be honest with you. Our testing includes a program that keeps the phone’s display on at all times, while Google is constantly performing an image search, one after the other. It’s an intense test, and at any point I can hop in and play a game, browse the web, send a text, make a call, etc. All in all, the One S lasted 4 hours and 51 minutes. T-Mobile 4G was on the entire time. To be honest, the phone got a bit warm during the battery test, but it didn’t slow things down or create a lag by any means. Plus, you’re probably not as much of a power user as our battery test is. In real world scenarios, the One S should surely stick with you all day. To give you a little context, the Droid 4 only hung in there for three hours and forty-five minutes while the Droid RAZR Maxx (Motorola’s battery beast) stayed with me for a staggering eight hours and fifteen minutes. Head-To-Head With The One X And iPhone 4S:
Hands-On Video: Fly or DieConclusionAs I expressed during Fly or Die, I think the One S will owe a lot of its success to its carrier. T-Mobile is a fine operator and I applaud the company for trying to rebrand and build up its selection. But without any competition from the iPhone, the One S gets a bit of a freebie. It’s a fine handset, but it has no real wow factor, as I’ve mentioned over and over. The Samsung Galaxy Note has its massive screen and an S-Pen (and might actually compete with the One S on T-Mo shelves), the Droid 4 has its superior physical keyboard, and the Lumia 900 (which also might be T-Mobile-bound) has Windows Phone. The One S has none of that — it’s just another Android phone. But that’s ok, because it’s an excellent Android phone. It has all the right dimensions, a comfortable weight, a premium feel in the hand, and a stunning design. It’s rather quick for an Android phone, and comes loaded with tons of fun software. I give it a fly. Check out all of our One S review posts here.
  |
| Lane Becker On How To ‘Plan Serendipity’ In Tech And Business [TCTV] Posted: 28 Apr 2012 01:00 PM PDT  Yesterday, Becker added “New York Times Bestselling Author” to his list of descriptors, when the book “Get Lucky: How to Put Planned Serendipity to Work for You and Your Business” which he wrote with his Get Satisfaction co-founder Thor Muller debuted at the number six spot on the NYT’s best seller list for hardcover advice and miscellaneous books (which is generally where business books are ranked.) It is also holding the number three spot on the Wall Street Journal’s hardcover business best seller list. So we were very pleased to have Lane Becker drop by the TechCrunch TV studio this week for an interview. Watch the video above to hear about what “planned serendipity” really is (you can’t plan to win the lottery, alas), how Steve Jobs literally architected good luck into Pixar and Apple, how luck plays into Amazon’s current status as a tech product hit factory, and how even rank-and-file employees can “storm the gates” to make their companies more open to success. Want more “Get Lucky” stuff? Becker’s co-author Muller wrote a guest post for TechCrunch which you can find right here.
  |
| The Seven Forces Disrupting Venture Capital Posted: 28 Apr 2012 12:32 PM PDT  Editor’s Note: TechCrunch columnist Semil Shah currently works at Votizen and is based in Palo Alto. You can follow him on Twitter @semil For the past few years, I have read over what seems like hundreds of blogs and thousands of tweets that either directly claim or indirectly hint at a disruption of traditional venture capital. For some, the factors relate to the economy, that limited partners and institutional investors were reviewing their investment approaches. For others, it seemed as if there was too much money in the asset class, that there was too much money chasing too few real opportunities. There seemed to be a long laundry list of why venture capital was undergoing this shift, but never any thread that could lay out all the factors and synthesize just how each factor contributed to shift, until now… (Note: 1. Since "venture capital" is applied to many different industries with vastly different economic structures, this post will focus on software startups. 2. I am not going to list examples below because there are too many and I don't want to exclude any particular companies.) First, we have Amazon: It's cheap to build, host, test, and optimize software. Amazon Web Services, for instance, reduce operational costs for young companies, directly impacting a startups' burn rate. Whereas in the past a not insignificant part of an investment may be allocated to hosting, Amazon's innovation has helped entrepreneurs better manage costs and dampened the need for venture capital investors to help out early with operational expenses. Secondly, Angel Investors: Once a products gets to some proof of concept, an entrepreneur can raise seed funding from an incredibly wide range of sources. Those that are either connected or lucky can solicit checks from family, friends, former bosses and colleagues, or they join incubators (more on this below), or reach out to relatively obscure or more well-known angel investors, all the way up to small institutional funds, what some people refer to as "Super Angels" or "MicroVCs," or websites dedicated to pairing investors with investment opportunities (more on this below). The flood of early-stage capital has triggered some venture capital firms to also invest in the seed stage, where they have to compete directly with smaller funds or vehicles, though a small handful of firms have resisted and focused on Series A-style investments. Third, we have AngelList: Simply one of the most disruptive forces to the venture industry, the folks behind AngelList have created extremely useful social software that pairs investors with investment opportunities. For angel investors, AngelList provides an asynchronous way to scout, monitor, track, and communicate with potential investment; for startups, the system provides an opportunity for them to network, build reputation and good signals, and connects them to a wider range of potential funders. The disruption AngelList provides to venture capital is that the system could theoretically be used for larger Series A and B fundings, and in some cases, probably has. It remains to be seen if it can scale across to this level, but given how much it has accomplished in a few years, it's not out of the question. Fourth, we have Kickstarter and crowdfunding: For some particular startups that aren't able to secure seed funds, either from angels, super angels, angel-focused software, or venture capitalists that make seed investments, they can leverage crowdfunding platforms like Kickstarter to tap into an even wider pool of available funds. And now with the JOBS Act, which will allow for crowdfunding of certain startups in certain situations, new companies can now raise small amounts of money from many different people, just as a political candidate may use small online donations from a large base to raise funds. Fifth, there's Y Combinator: While there seems to be an incubator popping up weekly nowadays, the system, network, and brand built by the partners at Y Combinator has, in a relatively short period of time, captured significant power in the early-stage ecosystem by attracting, vetting, and training technical entrepreneurs on the ins and outs of how to start technology companies. Each class in Y Combinator prepares for their Demo Day, and each company has the option to accept $150,000 in convertible debt — and not just from anyone (more on this below). Having this cash on hand affords these companies a bit more time and runway should they need it, and gives them some negotiating leverage when talking to larger investors who are keen to invest, sometimes resulting in higher valuations that venture capitalists have to compete against. Sixth, is "New" Venture Capital: The money given to these YC companies isn't just normal money — it's in part from a new style of venture capital pioneered by firms like Andreessen Horowitz (A16Z) and DST. While DST has made big bets and partnered with YC, A16Z has also raised large funds with a relatively small partnership, choosing instead to challenge the traditional venture capital personnel structure by operationalizing services across functional areas such as business development, recruiting, public relations, and sales. For a founder, the services offered in this model are strong, and this has motivated some other venture capital firms to change their own structures in an effort to provide more services to their companies. Additionally, the A16Z investment thesis, which seems to be designed around a belief that this is a particularly unique period of opportunity for transformation both on the web and in mobile and that a small share of winners in these categories will produce outsized returns. As a result, they seem to be willing to pay higher prices, which either forces traditional venture to compete or wait for the next thing. And, finally, seventh are secondary markets: Now that early-stage shareholders (investors, founders, employees) of certain companies can sell their shares on these secondary markets, such as SecondMarket or SharesPost, they are able to access liquidity much earlier in the past. On the flip side, larger venture capital funds that may have missed out on the next big thing because the new company was incubated, or crowdfunded, or funded via a social network or small or large angel investors may have a chance to own a piece of the entity through these markets. In some cases, venture capital firms have been quite opportunistic to buy and sell shares of larger web companies in a short period of time, making a quick flip and marketing to the world that they, too, have invested in a particular company. While these markets provide venture capital with access, they also have to compete with a larger number of firms for these deals, a factor that could drive up prices and thereby affect returns. All of these forces combined, and each individually in their own way, have altered the landscape for traditional venture capital in software. It is on average significantly more difficult to for traditional firms to find early-stage opportunities because there is more competition for those investments, and once a company does breakout and require more institutional funding, the prices for those rounds may not look like they have in the past. Some of this is reflective of the competitive forces that set market prices for private companies, or, depending on where you sit, is simply the new price to pay in order to own a piece of these coveted assets. And while we’re able to analyze what has happened so far, I have no clue what the next few years will hold. Will the next big breakout originate from an incubator, will it be funded by software platforms, or will it be discovered by a small set of angels and venture capitalists, as it has for so many years to date? In the great race to find incredible talent before others, and the great race to own shares in private companies, there are more questions here than answers, but there's no denying that it will be fascinating to see unfold. Photo Credit: Slack Pics / Creative Commons Flickr
  |
| Cyberpunks Rejoice: Kickstarter Project Aims To Resurrect Shadowrun Posted: 28 Apr 2012 10:46 AM PDT  If you spent any time in high school thinking about ley lines and bio-implants, you were probably a Shadowrun player. The game, which petered out after a disastrous run as a PC/Xbox game in 2007, brought the high-tech of William Gibson to the magical realms of Mr. Gygax. It was, in short, pretty cool. A Kickstarter project aims to bring back all that fun in video game form, adding lots of what you missed about Shadowrun back to the PC. This new version will be a RPG involving the Shadowrun world complete with various character types – elves, samurai, humans – and, although this is discouraged, deals with dragons. $15 gets you a copy of the game while $60 gets you a t-shirt and some in-game perks. Pledge $10,000 and the real magic happens: Previous rewards + Mike Mulvihill, who led Shadowrun game development at FASA Corp., will COME TO YOUR TOWN TO RUN A TABLETOP GAME OF SHADOWRUN FOR YOU AND FIVE OF YOUR FRIENDS. (He’ll even buy some snacks.) You can read about the game here or fund it over at Kickstarter. The game has already gained pledges of $2 million on a $400,000 goal, so there’s a good chance it will get made.
  |
| Gillmor Gang: The Teddy Bear Bubble Posted: 28 Apr 2012 10:00 AM PDT  The Gillmor Gang — John Borthwick, Danny Sullivan, John Taschek, and Steve Gillmor — took the bait and played the Are We in a Bubble game. With Apple’s stock price in free fall, the mobile giant reported another blowout What Me Worry quarter that sent the stock right back up. Meanwhile, Google announced, no, shipped Gdrive, and sent shivers down the collective cloud storage spine. What Gdrive really does is consolidate Google Office under an attractive layer of collaborative unification, borrowed first from Ray Ozzie’s Mesh service and now emulated by a raft of smaller players bubbling up from Startupville. While we’re all twisting slowly in the Apple wind, the real action is taking place in what the chat room somehow called the Teddy Bear Cloud. It’s the new binky. @stevegillmor, @dannysullivan, @borthwick, @jtaschek Produced and directed by Tina Chase Gillmor @tinagillmor
  |
| They Ain’t Making Any More of Them: The Great Engineering Shortage of 2012 Posted: 28 Apr 2012 10:00 AM PDT  Editor's note: This post is authored by guest contributor Jon Bischke. Jon is a founder of Entelo and is an advisor to several startups. You can follow Jon on Twitter here. Corner any up-and-coming Kevin Systrom wanna-be and have a heart-to-heart about the challenges of building a successful company and at some point you’ll likely wander into the territory of bemoaning how tough it is to hire people with technical skills. At a party recently a startup founder told me “If you could find me five great engineers in the next 90 days I’d pay you $400,000.” Which is crazy talk. Unless you stop to consider that Instagram’s team (mostly engineers) was valued at almost $80 million per employee or that corporate development heads often value engineers at startups they are acquiring at a half-million to million dollars per person. $400,000 actually might not be so crazy for a basketball lineup’s worth of guys who can sling Ruby or Scala code. So with all this widespread talk about the value of hiring great engineers and the apparent dearth of technical talent in the market, college students must be signing up to computer science classes in droves. This is the next California Gold Rush is it not? The era in which a self-taught programmer can emerge from relative obscurity and land a mid-nine figure payday. Engineering enrollments surely must be at an all-time high? Au contraire, mon frère. Consider this (from the Marginal Revolution blog):
Coding is as hot as it’s ever been and yet we graduated more students with CSci degrees in The Year of Our Orwell as we do today? What’s going on here exactly? A little more from the same blog post:
We are raising a generation of American Idols and So You Think You Can Dancers when what we really need is a generation of Gateses and Zuckerbergs. According to the Bureau of Labor Statistics (PDF download) computer and mathematical occupations are expected to add 785,700 new jobs from 2008 to 2018. It doesn’t take a math major to see that we’re graduating students at a far lower rate than required to meet demand. But what’s important is not just what is happening but also why it’s happening. If there’s both security on the downside (computer science majors experience rock-bottom unemployment rates) and untold riches on the upside, it seems the rational economic choice for people to flock to majoring in computer science and engineering. And yet, that’s not what’s taking place. Let’s look at a few of many theories as to why people might be choosing to study drama and music instead of C++ and algorithms. People don’t get excited by technology. The glamour and glitz of Hollywood that attracts thousands of Midwestern prom queens every year is undeniable. And the stereotype of the lone coder sitting alone in a cube somewhere can’t quite match up to the thrill, however unlikely, of one day performing in front of Steven, Randy and Jennifer. But that doesn’t seem entirely logical. After all, Sorkin did his best to put nerds front and center with The Social Network and show the rags-to-riches possibilities associated with tech entrepreneurship, at least to the extent that you’re allowed to ever consider a Harvard undergrad as a “rags-worthy” starting point. Furthermore, you need look no further than the Forbes 400 to see alpha geeks racing yachts and buying sports teams. And of course there has never been a time in history when technology was more ubiquitous, with all of us carrying an incredibly powerful computing device in our pockets. Technology is hard. OK, now perhaps we’re getting a little closer to the truth. It’s not that learning how to program has gotten noticeably more difficult over the years. If anything, frameworks like Rails for Ruby make it easier. But there is a basic level of understanding that, if you don’t have it, drastically reduces the likelihood that you’ll become an engineer. Indeed, at each level of our education there’s a chance to miss out on fundamental knowledge that, if not acquired at that point, becomes progressively more difficult to pick up later in life. Salman Khan said it best in his TED talk that should be mandatory viewing:
There’s likely, in part at least, an education challenge here. But it’s doesn’t appear to be just that. There’s something else important here. There’s little incentive, early in one’s career, to choose to go into computer science or engineering. At the time you’re choosing your career path, say around 20 years of age, you often haven’t fully digested that the rational economic choice for your studies is something in the STEM disciplines. And when all things are the same “price” (i.e., a degree in the humanities costs the same as a degree in engineering) if you don’t internalize that the net present value of that diploma with a computer science major is significantly greater than the net present value of that diploma with a drama major then maybe drama isn’t such an irrational choice. Therein lies the problem. If a drama major costs society substantially more than a computer science major (e.g., drama majors pay less taxes, draw more unemployment benefits, etc.) then perhaps a drama major should be more expensive than a computer science major? While this sounds, no pun intended, dramatic, it’s worthwhile to consider that China is canceling majors they don’t deem to have good employment prospects. Or maybe there isn’t a big problem here after all. Before we completely overhaul the incentive process around how students choose their major perhaps there’s another thing worth considering and that’s the rise of self-directed learning services and websites such as Codecademy, CodeLesson, General Assembly, Dev Bootcamp, Treehouse and Udemy (Disclosure: I’m an advisor to Udemy) make the lower numbers of college graduates with computer science degrees less disconcerting. After all, the important thing is that people are acquiring these skills, not necessarily that they are majoring in the discipline. There is a lot to think about here and no easy answers but a dialogue on the topic seems important. After all, some of the most innovative companies on the planet are starved for talent while at the same time job prospects for new college graduates are pretty bleak. What will it take to resolve that paradox?
  |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| You are subscribed to email updates from TechCrunch To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |